
(Source of image: Author provided)
Introduction
Hi! My name is Fajar Muhammad Hamka, and I am an AI Engineer at Money Forward in the AI Development Division. When I first heard about RAG (Retrieval-Augmented Generation), the name sounded complicated, but the concept is actually quite simple and incredibly powerful. In this article, I’ll explain RAG in the simplest way possible. We’ll build a customer support bot together, and I’ll explain every single step of how it works. By the end, you’ll understand why RAG is becoming essential for building AI applications that need to work with your own data.
The Problem: Why Do We Need RAG?
Let me start with a real problem. Imagine you run an online electronics store called “JarMart” You want to build a chatbot to answer customer questions like:
- “What’s your return policy?”
- “Does the Fajar XX-123XYZ headphone come with a case?”
- “How long does shipping take to Tokyo?”
Why Can’t We Just Use GenAI Tools Directly?
You might think: “Easy! I’ll just use GenAI Tools.” But there’s a problem:
- GenAI Tools doesn’t know about YOUR store – It doesn’t know your specific return policy, your product details, or your shipping times
- GenAI Tools might make things up – It could invent a return policy that sounds good but isn’t yours
- GenAI Tools’s knowledge is outdated – It doesn’t know about products released after its training cutoff date
This is where RAG comes in!
What is RAG? The Library Analogy
Think of RAG like a smart student using a library:
Without RAG (Regular GenAI Tools):
- Student answers from memory only
- Might misremember or make up facts
- Can’t access new information
With RAG (Our Goal):
- Student goes to the library (your documents)
- Finds relevant books/pages (retrieval)
- Reads them and answers based on what they found (generation)
- Cites which books they used
RAG stands for Retrieval-Augmented Generation:
- Retrieval = Finding relevant information from your documents
- Augmented = Adding that information to the AI’s context
- Generation = AI generates an answer based on the retrieved information
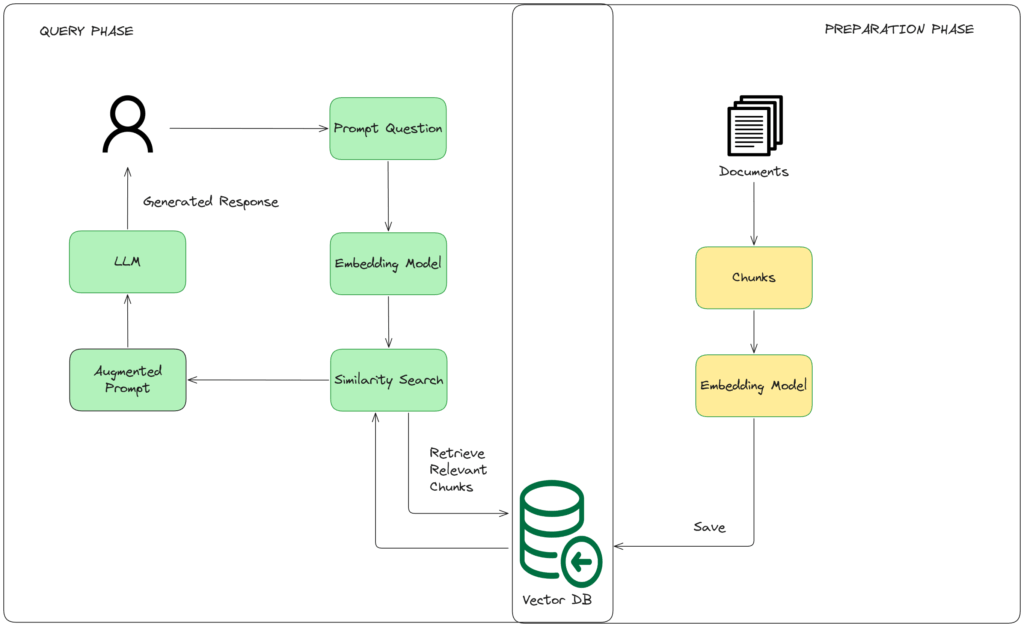
How RAG Works: The Complete Picture
Let me break down the entire RAG process step by step:
Step 1: Preparation Phase (One-Time Setup)
Imagine you have a document with your store policies:
JarMart Return Policy:
All electronics can be returned within 30 days of purchase.
Items must be in original packaging with all accessories.
Refunds are processed within 5-7 business days.
Shipping Information:
Standard shipping takes 3-5 business days within Japan.
Express shipping takes 1-2 business days.
Free shipping on orders over 5,000 yen.
Here’s what happens in preparation:
1.1 Break Documents into Chunks
What is chunking?
Imagine you have a long book. Instead of giving someone the entire book to find one answer, you tear out individual pages or paragraphs. Now they can quickly find the exact page that answers their question!
Chunking is the same idea: breaking a big document into smaller pieces.
Why do we need chunking?
Two main reasons:
- AI has limited memory – Just like you can’t remember an entire encyclopedia, AI can only process a limited amount of text at once (usually a few thousand words)
- We want specific answers – If someone asks “What’s your return policy?”, we only want to give them the return policy section, not your entire 100-page manual!
Example – Before Chunking:
[ONE BIG DOCUMENT - 50 pages]
Return policy... shipping info... warranty... products...
contact info... payment methods... etc etc...
When someone asks “How many days for returns?”, the AI has to read ALL 50 pages. Slow and confusing!
Example – After Chunking:
Chunk 1: Return Policy (just this topic)
Chunk 2: Shipping Info (just this topic)
Chunk 3: Warranty Info (just this topic)
Chunk 4: Product Details (just this topic)Now when someone asks “How many days for returns?”, we only grab Chunk 1. Fast and accurate!
Simple Chunking Example:
Let’s say we have this document:
JarMart Return Policy: All electronics can be returned
within 30 days of purchase. Items must be in original
packaging with all accessories.
Refunds are processed within 5-7 business days.
Shipping Information: Standard shipping takes 3-5 business
days within Japan. Express shipping takes 1-2 business days.
Free shipping on orders over 5,000 yen.We break it into smaller pieces:
✂️ Chunk 1:
"JarMart Return Policy: All electronics can be returned
within 30 days of purchase. Items must be in original
packaging with all accessories."
✂️ Chunk 2:
"Refunds are processed within 5-7 business days."
✂️ Chunk 3:
"Shipping Information: Standard shipping takes 3-5 business
days within Japan. Express shipping takes 1-2 business days."
✂️ Chunk 4:
"Free shipping on orders over 5,000 yen."
Each chunk is like a sticky note with one topic!
1.2 Convert Chunks to “Embeddings” (Magic Numbers)
This is the trickiest concept, so let me explain it simply:
What are embeddings?
Embeddings are a way to convert text into numbers so computers can understand meaning and similarity.
Think of it like converting colors to RGB:
- Red = (255, 0, 0)
- Orange = (255, 165, 0)
- Yellow = (255, 255, 0)
You can tell Red and Orange are more similar than Red and Yellow by comparing the numbers!
For text, it works the same way:
- “return policy” might become [0.2, 0.8, 0.1, 0.9, …]
- “refund policy” might become [0.3, 0.7, 0.2, 0.85, …]
- “shipping costs” might become [0.1, 0.2, 0.9, 0.1, …]
The computer can see “return policy” and “refund policy” are similar because their numbers are close!
1.3 Store in a “Vector Database”
This is just a special storage system optimized for finding similar numbers quickly. Think of it like a super-efficient filing cabinet that can find “documents similar to this one” instantly.
Step 2: Query Phase (Every Time a Customer Asks a Question)
Now a customer asks: “How many days do I have to return a product?”
Here’s what happens:
2.1 Convert the Question to Embeddings
The question “How many days do I have to return a product?” is converted to numbers the same way:
- Question becomes → [0.25, 0.75, 0.15, 0.88, …]
2.2 Find Similar Chunks (The “Retrieval” Part)
The system compares the question’s numbers with all stored chunk numbers and finds the most similar ones:
Most Similar Chunks:
✓ Chunk 1: "All electronics can be returned within 30 days..." (95% match)
✓ Chunk 2: "Refunds are processed within 5-7 business days." (70% match)
✗ Chunk 3: "Shipping Information..." (20% match - not relevant)
✗ Chunk 4: "Free shipping on orders..." (15% match - not relevant)
2.3 Create a Smart Prompt (The “Augmented” Part)
Now we create a special prompt for the AI:
You are a customer support assistant for JarMart.
Here is relevant information from our documentation:
---
JarMart Return Policy: All electronics can be returned
within 30 days of purchase. Items must be in original
packaging with all accessories.
Refunds are processed within 5-7 business days.
---
Customer Question: How many days do I have to return a product?
Answer the question based ONLY on the information provided above.
If you don't find the answer in the information, say "I don't know."
2.4 AI Generates Answer (The “Generation” Part)
The AI reads the context and generates:
"You have 30 days from the date of purchase to return electronics.
Please ensure the item is in its original packaging with all
accessories included."
The AI doesn’t make this up – it’s directly answering based on the retrieved documents!
Let’s Build It: Step-by-Step Tutorial
Now let’s actually build this! I’ll show you the code, but more importantly, I’ll explain what each part does and WHY.
Setup
Create a new folder for your project and install these tools:
requirements.txt:
openai==1.12.0
chromadb==0.4.22
sentence-transformers==2.5.1These are:
openai– To use OpenAI LLMchromadb– Our vector database (filing cabinet for embeddings)sentence-transformers– To convert text to embeddings locally (free!)
Install them:
pip install -r requirements.txtCreate Sample Store Documentation
store_policies.txt:
JarMart Return Policy:
All electronics can be returned within 30 days of purchase if you're not satisfied.
Items must be in original packaging with all accessories included.
The product must be in unused or like-new condition.
Refunds are processed within 5-7 business days after we receive the returned item.
You can initiate a return by contacting our support team or through your account dashboard.
JarMart Shipping Information:
We offer two shipping options for customers in Japan.
Standard shipping takes 3-5 business days and costs 500 yen.
Express shipping takes 1-2 business days and costs 1,200 yen.
Free standard shipping is available on all orders over 5,000 yen.
We currently only ship within Japan.
JarMart Warranty Information:
All electronics come with a 1-year manufacturer warranty.
Extended warranty plans are available for purchase at checkout.
Warranty covers manufacturing defects but not accidental damage.
To claim warranty, keep your purchase receipt and contact our support team.
Product: Fajar XX-123XYZ Headphones:
Price: 45,000 yen
These premium noise-cancelling headphones feature industry-leading noise cancellation.
Battery life: Up to 30 hours with ANC on, 40 hours with ANC off.
Includes: Carrying case, USB-C charging cable, audio cable, and airplane adapter.
Available in two colors: Black and Silver.
Product: Fajar Phone A12:
Price: 159,800 yen
The latest Fajar Phone with Premium chip and titanium design.
Storage options: 128GB, 256GB, 512GB, 1TB.
Camera: 48MP main camera with 5x optical zoom.
Includes: USB-C charging cable and documentation (no power adapter).
Available in four colors: Natural Titanium, Blue Titanium, White Titanium, Black Titanium.Build the Customer Support Bot – Version 1 (Simple)
Let me show you the simplest version first, with detailed comments explaining EVERYTHING:
support_bot_simple.py:
import chromadb
from sentence_transformers import SentenceTransformer
from openai import OpenAI
# ==========================================
# STEP 1: LOAD OUR STORE DOCUMENTATION
# ==========================================
# Read the store policies from the file
with open("store_policies.txt", "r", encoding="utf-8") as f:
full_document = f.read()
# Print so you can see what we loaded
print("📄 Loaded store documentation:")
print(full_document[:200] + "...\n")
# ==========================================
# STEP 2: BREAK INTO CHUNKS
# ==========================================
# Why? Because we want to find specific, relevant pieces of information
# We'll split by double newlines (paragraph breaks)
chunks = full_document.split("\n\n")
# Remove empty chunks and clean up
chunks = [chunk.strip() for chunk in chunks if chunk.strip()]
print(f"✂️ Split document into {len(chunks)} chunks")
print(f"Example chunk: '{chunks[0][:100]}...'\n")
# ==========================================
# STEP 3: CONVERT CHUNKS TO EMBEDDINGS
# ==========================================
# This is where we convert text to numbers!
# We use a free model that runs on your computer
print("🔢 Converting text to embeddings (numbers)...")
# Load the embedding model
# "all-MiniLM-L6-v2" is a good, fast, free model
embedding_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Convert each chunk to embeddings
chunk_embeddings = embedding_model.encode(chunks)
print(f"✅ Created embeddings with {len(chunk_embeddings[0])} dimensions")
print(f"Example: '{chunks[0][:50]}...' → [{chunk_embeddings[0][:3]}...]")
print()
# ==========================================
# STEP 4: STORE IN VECTOR DATABASE
# ==========================================
# This is our smart filing cabinet!
print("💾 Storing embeddings in vector database...")
# Create a ChromaDB client that persists to disk
# This will create a folder called "chroma_db" in your project directory
client = chromadb.PersistentClient(path="./chroma_db")
# Try to get existing collection, or create new one
try:
collection = client.get_collection(name="store_docs")
print("✅ Loaded existing database from disk\n")
except:
collection = client.create_collection(name="store_docs")
# Store each chunk with its embedding (only if creating new)
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
collection.add(
ids=[f"chunk_{i}"], # Unique ID for each chunk
embeddings=[embedding.tolist()], # The numbers
documents=[chunk], # The actual text
)
print(f"✅ Stored {len(chunks)} chunks in database\n")
# ==========================================
# STEP 5: SETUP OPENAI FOR ANSWERING
# ==========================================
# You need an OpenAI API key for this part
# Get one at: https://platform.openai.com/api-keys
openai_client = OpenAI(api_key="YOUR_API_KEY")
# ==========================================
# STEP 6: THE QUERY FUNCTION - THIS IS RAG!
# ==========================================
def ask_question(question):
"""
This function takes a question and returns an answer using RAG
"""
print(f"\n{'='*60}")
print(f"❓ Question: {question}")
print(f"{'='*60}\n")
# STEP 6.1: Convert question to embeddings
print("1️⃣ Converting question to embeddings...")
question_embedding = embedding_model.encode([question])[0]
print(f" → Question converted to {len(question_embedding)} numbers\n")
# STEP 6.2: Find similar chunks (THE RETRIEVAL PART!)
print("2️⃣ Searching for relevant information...")
results = collection.query(
query_embeddings=[question_embedding.tolist()],
n_results=3 # Get top 3 most similar chunks
)
retrieved_chunks = results['documents'][0]
print(f" → Found {len(retrieved_chunks)} relevant chunks:")
for i, chunk in enumerate(retrieved_chunks):
print(f" {i+1}. {chunk[:80]}...")
print()
# STEP 6.3: Create context from retrieved chunks
context = "\n\n".join(retrieved_chunks)
# STEP 6.4: Build the prompt for GenAI Tools (THE AUGMENTED PART!)
print("3️⃣ Creating prompt with retrieved information...\n")
prompt = f"""You are a helpful customer support assistant for JarMart, an electronics store.
Here is relevant information from our store documentation:
---
{context}
---
Customer Question: {question}
Instructions:
- Answer based STRICTLY and ONLY on the information provided above
- Do NOT use any external knowledge or make assumptions
- If the specific information is not in the context above, you MUST say "I don't have that information in our documentation"
- Do NOT suggest that we might have products unless they are explicitly mentioned in the context
- Be helpful and friendly, but stay within the bounds of the provided information
Answer:"""
# STEP 6.5: Get answer from GenAI Tools (THE GENERATION PART!)
print("4️⃣ Asking GenAI Tools to generate an answer...\n")
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
],
temperature=0 # 0 = more focused, less creative
)
answer = response.choices[0].message.content
# Display the answer
print(f"{'='*60}")
print(f"💬 ANSWER:")
print(f"{'='*60}")
print(answer)
print(f"{'='*60}\n")
return answer
# ==========================================
# STEP 7: TEST IT!
# ==========================================
if __name__ == "__main__":
print("\n🤖 JarMart Customer Support Bot Ready!\n")
# Test with different questions
test_questions = [
"How many days do I have to return a product?",
"What comes with the Fajar headphones?",
"How much does express shipping cost?",
"Do you sell laptops?" # This should say "I don't have that info"
]
for question in test_questions:
ask_question(question)
input("Press Enter to continue to next question...")Running This Script:
To run this script, execute the following command:
python support_bot_simple.pyNote: The first run might take some time because it will download a model from SentenceTransformers.
Understanding the Output
When you run this code, you’ll see detailed output showing each step:
📄 Loaded store documentation:
JarMart Return Policy:
All electronics can be returned within 30 days...
✂️ Split document into 9 chunks
Example chunk: 'JarMart Return Policy:...'
🔢 Converting text to embeddings (numbers)...
✅ Created embeddings with 384 dimensions
Example: 'JarMart Return Policy:...' → [0.043, -0.028, 0.015...]
💾 Storing embeddings in vector database...
✅ Stored 9 chunks in database
🤖 JarMart Customer Support Bot Ready!
============================================================
❓ Question: How many days do I have to return a product?
============================================================
1️⃣ Converting question to embeddings...
→ Question converted to 384 numbers
2️⃣ Searching for relevant information...
→ Found 3 relevant chunks:
1. JarMart Return Policy: All electronics can be returned within 30 days...
2. Refunds are processed within 5-7 business days after we receive...
3. You can initiate a return by contacting our support team...
3️⃣ Creating prompt with retrieved information...
4️⃣ Asking GenAI Tools to generate an answer...
============================================================
💬 ANSWER:
============================================================
You have 30 days from the date of purchase to return electronics.
Items must be in original packaging with all accessories and in
unused or like-new condition. You can start a return by contacting
our support team or through your account dashboard.
============================================================
What’s Happening Here?
Let me explain the magic:
- The question “How many days do I have to return a product?” gets converted to 384 numbers
- The system searches through all stored chunks and finds the return policy chunk is most similar
- It retrieves the top 3 most relevant chunks
- It creates a prompt that includes these chunks as context
- GenAI Tools reads the context and answers based on it
- The answer is accurate because it’s based on your actual policies, not made up!
Why is This Better Than Just Using GenAI Tools?
Let me show you the difference:
Without RAG (Regular GenAI Tools):
Q: "What comes with the Fajar XX-123XYZ headphones from JarMart?"
A: "I don't have specific information about JarMart's offerings..."
With RAG (Our Bot):
Q: "What comes with the Fajar XX-123XYZ headphones?"
A: "The Fajar XX-123XYZ headphones include a carrying case,
USB-C charging cable, audio cable, and airplane adapter."
The RAG version knows YOUR specific product details!
Improving the System: Better Chunking
The first version works, but we can make it smarter. Let me explain the problem first.
The Problem with Simple Chunking
Imagine you’re cutting a pizza into slices. If you cut EXACTLY between two different toppings, you might lose important information!
Example Problem:
Let’s say we have this text about returns:
"All electronics can be returned within 30 days.
Items must be in original packaging.
Contact our support team to start the return process."
Bad Chunking (Cut in the wrong place):
Chunk 1: "All electronics can be returned within 30 days."
Chunk 2: "Items must be in original packaging."
Chunk 3: "Contact our support team to start the return process."
What’s the problem?
If someone asks: “What are the full requirements for returns?”
The system might only grab Chunk 1, which says “30 days” but MISSES the packaging requirement and how to contact support!
The answer would be incomplete! ❌
Solution: Smart Chunking with Overlap
The Photo Analogy:
Imagine taking photos of a long wall mural:
Bad Approach (No Overlap):
[Photo 1: LEFT side] [Photo 2: MIDDLE] [Photo 3: RIGHT side]
❌ Gap ❌ Gap
You might miss important details between photos!
Smart Approach (With Overlap):
[Photo 1: LEFT to MIDDLE]
[Photo 2: MIDDLE to RIGHT]
✓ Overlap!
Now each photo shares some content with the next one. Nothing gets lost!
Applying This to Text Chunks:
Instead of cutting text cleanly, we make chunks that OVERLAP. Each chunk shares some text with the previous and next chunk.
Example – Smart Chunking:
Original Text:
"All electronics can be returned within 30 days.
Items must be in original packaging.
Contact our support team to start the return process."
✂️ Chunk 1 (with extra text at the end):
"All electronics can be returned within 30 days.
Items must be in original packaging."
↓ OVERLAP ↓
✂️ Chunk 2 (starts earlier, includes some repeated text):
"Items must be in original packaging.
Contact our support team to start the return process."
Notice how “Items must be in original packaging” appears in BOTH chunks? That’s the overlap!
Why This Helps:
Now when someone asks about return requirements:
- Chunk 1 has: 30 days + packaging requirement ✓
- Chunk 2 has: packaging requirement + contact info ✓
Either chunk gives more complete information!
How Much Overlap is Good?
Think of it like this:
No Overlap (0%):
[Chunk 1] [Chunk 2] [Chunk 3]
Risk: Missing context between chunks ❌
Small Overlap (10-20%):
[Chunk 1____]
[Chunk 2____]
[Chunk 3____]
Good balance! ✓
Too Much Overlap (50%+):
[Chunk 1_________]
[Chunk 2_________]
[Chunk 3_________]
Wastes space, costs more ❌
Best practice: 10-20% overlap (e.g., 50 characters overlap on a 300-character chunk)
How Smart Chunking Works
Here’s the process step by step:
Step 1: Set chunk size (e.g., 300 characters)
Step 2: Set overlap size (e.g., 50 characters)
Step 3: Create chunks:
- Chunk 1: Characters 0-300
- Chunk 2: Characters 250-550 (starts 50 chars before Chunk 1 ended!)
- Chunk 3: Characters 500-800 (starts 50 chars before Chunk 2 ended!)
- And so on…
Visual Example:
[0---------250--------300] ← Chunk 1
[250--------550] ← Chunk 2 (overlaps from 250-300)
[500--------800] ← Chunk 3 (overlaps from 500-550)
Simple Code Implementation
Here’s a simple function that does smart chunking:
```python
def smart_chunk_text(text, chunk_size=300, overlap=50):
"""
Break text into overlapping chunks
Args:
text: Your full document as a string
chunk_size: How many characters per chunk (default: 300)
overlap: How many characters to overlap (default: 50)
Returns:
A list of text chunks
"""
chunks = []
start = 0
# Keep creating chunks until we've covered the whole text
while start < len(text):
# Get the end position for this chunk
end = start + chunk_size
# Extract the chunk
chunk = text[start:end]
# Add this chunk to our list
chunks.append(chunk)
# Move to the next position (with overlap!)
# If chunk_size=300 and overlap=50, we move forward only 250 characters
start = start + chunk_size - overlap
return chunks
# Example usage:
document = """JarMart Return Policy: All electronics can be returned
within 30 days of purchase. Items must be in original packaging.
Contact our support team to start the return process."""
# Create chunks with 100 character size and 20 character overlap
chunks = smart_chunk_text(document, chunk_size=100, overlap=20)
print(f"Created {len(chunks)} chunks:")
for i, chunk in enumerate(chunks):
print(f"\nChunk {i+1}:")
print(chunk)
# Next step: Save these chunks to your vector database
# (Use the same method shown in the main code earlier)Output:
Created 3 chunks:
Chunk 1:
JarMart Return Policy: All electronics can be returned
within 30 days of purchase. Items must
Chunk 2:
Items must be in original packaging.
Contact our support team to start the
Chunk 3:
start the return process.
Notice how “Items must” appears in both Chunk 1 and Chunk 2? That’s the overlap working!
That’s it! Smart chunking is just making sure chunks share a bit of text with each other so we don’t lose important context.
Once you have your chunks ready, you can save them to your vector database using the same method we showed in the main code earlier (converting to embeddings and storing in ChromaDB). The smart chunking function simply replaces the basic text.split("\n\n") approach – everything else stays the same!
When to Use Smart Chunking?
Use simple chunking when:
- Your documents have clear sections (like product manuals with headings)
- Each section is independent
Use smart chunking when:
- Information flows continuously (like articles, policies)
- You want to be extra safe about not missing context
- You’re getting incomplete answers with simple chunking
Common Questions and Misconceptions
Q1: “Is RAG expensive to run?”
A: Not really! Here’s the cost breakdown:
- Embeddings: FREE if you use local models (sentence-transformers)
- Vector Database: FREE if you use ChromaDB locally
- LLM API calls: Only pay when users ask questions (few cents per question)
Q2: “How many documents can RAG handle?”
A: RAG scales well! Our simple example uses 9 chunks, but you can easily handle:
- 1,000 documents = Works fine on a laptop
- 100,000 documents = Need better vector database
- Millions = Use enterprise solutions
Q3: “Will RAG work in Japanese?”
A: Yes! Just use multilingual embedding models:
# Use this instead
embedding_model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')Q4: “What if the answer isn’t in my documents?”
A: The AI should say “I don’t have that information” (if you prompt it correctly). Let’s test:
ask_question("Do you sell cars?")
# Answer: "I don't have information about selling cars in our documentation."Q5: “Can I use this without OpenAI?”
A: Yes! You can use open-source models:
# Instead of OpenAI, use a local model
from transformers import pipeline
generator = pipeline('text-generation', model='mistral-7b')Real-World Tips from Production Use
Tip 1: Always Monitor Retrieved Chunks
Add logging to see what chunks are being retrieved:
```python
def ask_question_with_monitoring(question):
# ... retrieve chunks ...
# Log what was retrieved
print(f"📊 Retrieval Quality Report:")
for i, chunk in enumerate(retrieved_chunks):
print(f" Chunk {i+1} (first 100 chars): {chunk[:100]}...")
# This helps you debug if answers are wrong!Tip 2: Test Edge Cases
Always test:
- Questions with no answer in docs
- Questions mixing multiple topics
- Questions in different languages
- Very short questions (“Price?”)
- Very long questions
Tip 3: Update Documents Regularly
The beauty of RAG is you can update your knowledge base anytime:
# Add new product
new_product = """
Product: Fajar Phone A16:
Price: 140,000 yen
Features: AI-powered camera
"""
# Re-run the embedding and storage steps
# No need to retrain any models!Tip 4: Use Metadata for Better Filtering
Add categories to chunks:
collection.add(
ids=[f"chunk_{i}"],
embeddings=[embedding.tolist()],
documents=[chunk],
metadatas=[{"category": "return_policy", "last_updated": "2025-11-12"}]
)
# Later, search only in specific categories
results = collection.query(
query_embeddings=[question_embedding],
where={"category": "return_policy"}
)When RAG is NOT the Right Solution
RAG isn’t always the answer! Don’t use RAG when:
❌ You need calculations or logic
- Example: “Calculate tax on a 10,000 yen order”
- Better solution: Write actual code functions
❌ You need real-time data
- Example: “What’s the current stock price?”
- Better solution: API integration
❌ Your documents are too simple
- Example: Just 5 FAQ items
- Better solution: Use simple keyword matching
❌ You need to modify data
- Example: “Update my shipping address”
- Better solution: Traditional CRUD operations
RAG is best for: Answering questions based on your documents and knowledge base.
Conclusion: Why RAG Matters
Let me summarize what we’ve learned:
RAG solves a real problem:
- LLMs alone don’t know your specific business data
- RAG connects LLMs to your documents
- Reduces hallucinations and incorrect answers
How RAG works (simple version):
- Break documents into chunks
- Convert chunks to numbers (embeddings)
- Store in a vector database
- When a question comes, find similar chunks
- Feed chunks to the LLM as context
- LLM answers based on your actual data
Why this matters for real applications:
- Customer support bots that actually know your products
- Internal assistants that search company documentation
- Q&A systems that stay up-to-date
- Cost-effective alternative to fine-tuning
I hope this guide helps you understand RAG from the ground up! The key is to grasp the fundamental concepts first, then you can explore more advanced techniques as needed. Remember, the goal is always to provide accurate, helpful information to your users – that’s what aligns with Money Forward’s value of User Focus.
Happy building!