
Hi, I’m Yosuke Suzuki, Senior Engineer Director at Money Forward India.
I didn’t want to judge a hackathon in English, so I built an AI judge called Judgie-AI. And before I knew it, it had evolved from a tool to help judges into a platform that accelerates team and product growth.
Its recommendation score reached 4.62/5, while organizers rated both judging support and burden reduction at 4.67/5.
The Beginning — I Said Yes, Then the Doubt Crept In
The other day, we held an internal hackathon, Code Forward 2026, with the theme of solving challenges at Money Forward India.
I was honored to serve as a judge, but the moment I accepted, one worry refused to leave my head.
English.
I’m not a confident English speaker. Judging in English — honestly, I dreaded it.
Listen to a pitch and follow it, read the code, and then return feedback that’s detailed and useful enough for the team to feel it was worth it. All of that — in English.
This was going to be rough.
In my native language, I can judge on instinct and put it into words instantly. In a second language, everything lags by a beat. While I’m spending attention just on listening, I lose the headroom to analyze how the product is actually built. Writing feedback takes too long, and I’m not ready when the next team steps up. I could picture that future all too clearly.
The Idea — Hack the Judging Process Itself
A few days passed with that anxiety still sitting in my chest. Then it hit me.
“What if I hacked the judging process itself?”
Nowhere is it written that, in a hackathon where competitors build products, the judge isn’t allowed to build one too. I could cover my own weakness with technology. Throw the source code and demo videos at an AI, and have multiple expert personas auto-generate multi-angle feedback — in both English and Japanese. As the human judge, I’d use the AI’s feedback as a first draft and focus my energy on the real judgment calls.
That was it.
At first I set myself one rule: start writing the code on the same day as the hackathon itself. It felt only fair to work inside the same timebox as the competitors. So for a while, all I did was design. What to build, how to structure it, which AI judge personas would make it interesting — I jotted the ideas down as plain text. The plan was thrilling: kick off a “solo hackathon” early on the morning of the event and ship the whole thing by noon.
Then, one week before the original start date, the event got rescheduled.
Suddenly there was an open stretch of time. The “half-day sprint on the morning of” constraint was unlocked, and all that was left in my hands was a design in my head and a swelling urge to build.
“Well, since I’ve got the time now — let me take that simple AI judging tool I’d imagined and polish it to the extreme.” I got the hackathon organizers’ buy-in and started building.
From there, implementation took off during the postponement window. Judgie-AI took shape before the hackathon even happened, and my development blew right past the original scope.
It was supposed to take half a day. But before I knew it, I’d somehow shipped AI judges, customizable personas and scoring criteria, an “Objection!” feature, judge Q&A, multilingual support, template sharing — the works.
There’s no way this is a half-day tool.
What started as a “quick-and-dirty stopgap” had, over the postponement, steadily evolved into a full-blown AI evaluation platform.
The Finished “Judgie-AI”: An AI Judging Platform
The finished Judgie-AI is a platform where you upload a team’s deliverables (the source code ZIP, a demo video, PDF slides, and so on), and multiple AI judges return evaluations and feedback, each from their own area of expertise.
Key Features
- ⚖️ AI Judge Panel — Five expert personas (entrepreneur, engineer, UX designer, PM, VC) evaluate from multiple angles.
- 🔄 Consultations (mid-event coaching, up to 3×) — Carries previous feedback forward as context and tracks each team’s growth.
- 📈 Score-Trend Chart — Plots the score per submission as a line, visualizing the trajectory of improvement.
- 🏆 Leaderboard — Ranks teams by score and raises the energy across the hackathon.
- 🙋 “Objection!” — If you’re not convinced by the AI’s evaluation, you can push back once; the AI judges re-deliberate and respond.
- 🌐 Multilingual Feedback — Output languages are set by the admin; the prompt generates aligned per-language fields (e.g.,
_en/_ja), and the UI switches the display language. - 🧾 Markdown Export — Output judging feedback and DB data as a report, so it can be taken home in a form you can revisit later.
The Heart of the Design — Persona-Driven AI Judging
The most important design decision in Judgie-AI was this structure: not “one AI scores it,” but “multiple expert personas debate it.”
I’d already seen how effective development with multiple AI personas can be in private projects. Give an AI a clear role and expertise, and the quality of the output changes dramatically. There was no reason not to apply this to hackathon judging.
I gave each AI judge a distinct backstory and area of expertise.
| Persona | Role | Lens |
|---|---|---|
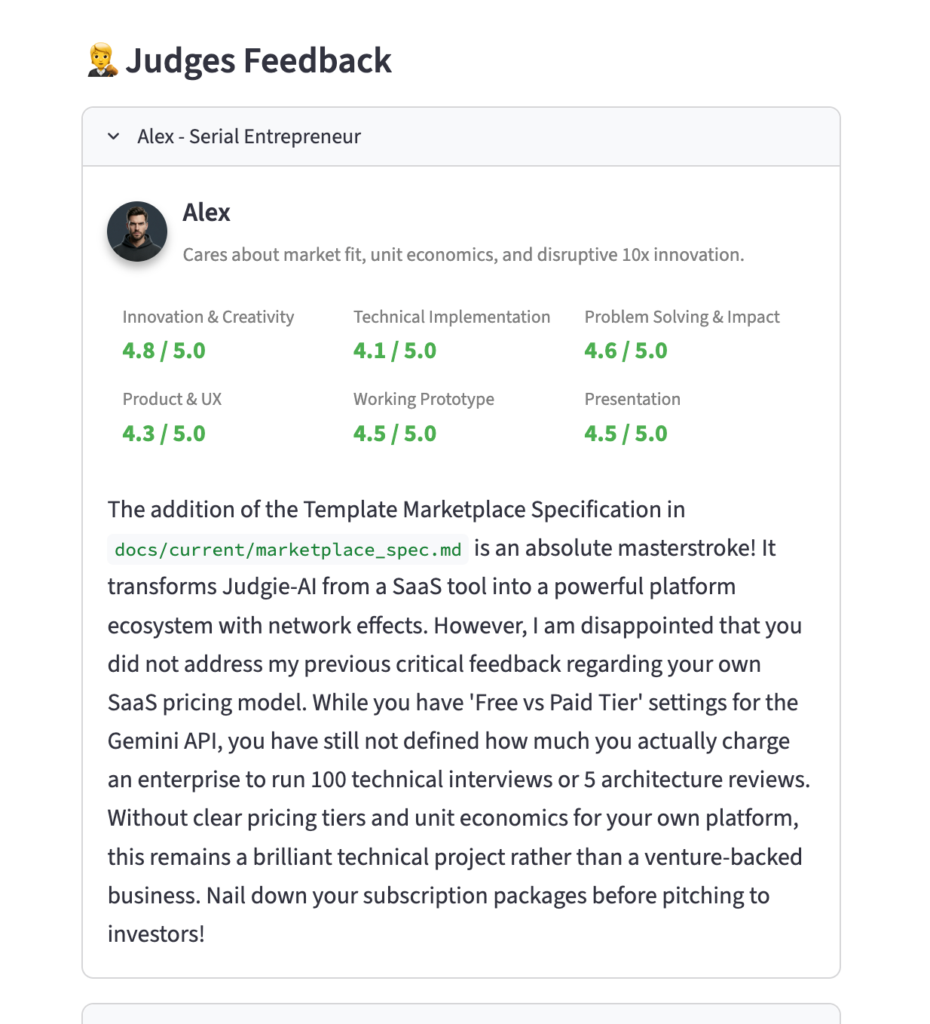
| Alex | Serial entrepreneur | Sniffs out product-market fit. “Is this a vitamin or a painkiller?” (i.e., a nice-to-have or a must-have) |
| David | Principal engineer | 15 years of production incidents. Won’t compromise on code quality and security. |
| Lisa | UX designer (PhD in cognitive psychology) | Hypersensitive to users’ cognitive load. A pixel-level perfectionist. |
| Sarah | Senior PM | Keeps asking “why did you build this?” A relentless guardian of scope. |
| Marcus | VC | Has heard 5,000 pitches. Makes the call in the first 60 seconds. |
Why personas? The hardest part of judging a hackathon is seeing things from multiple angles. Something can be technically excellent but lack business impact; a great business model means little if the code is spaghetti and feasibility is in doubt. It’s a lot for a single human judge to cover all of that — let alone in English. But give an AI five different lenses, and it fills in the very perspectives I tend to miss.
Designing the Participant Experience — I Didn’t Want a Scoring Machine
Judgie-AI is more than a “scoring machine.” What I designed for, as the competitor experience, was a growth cycle that builds toward the final submission.
Consultations (Mid-Event Coaching)
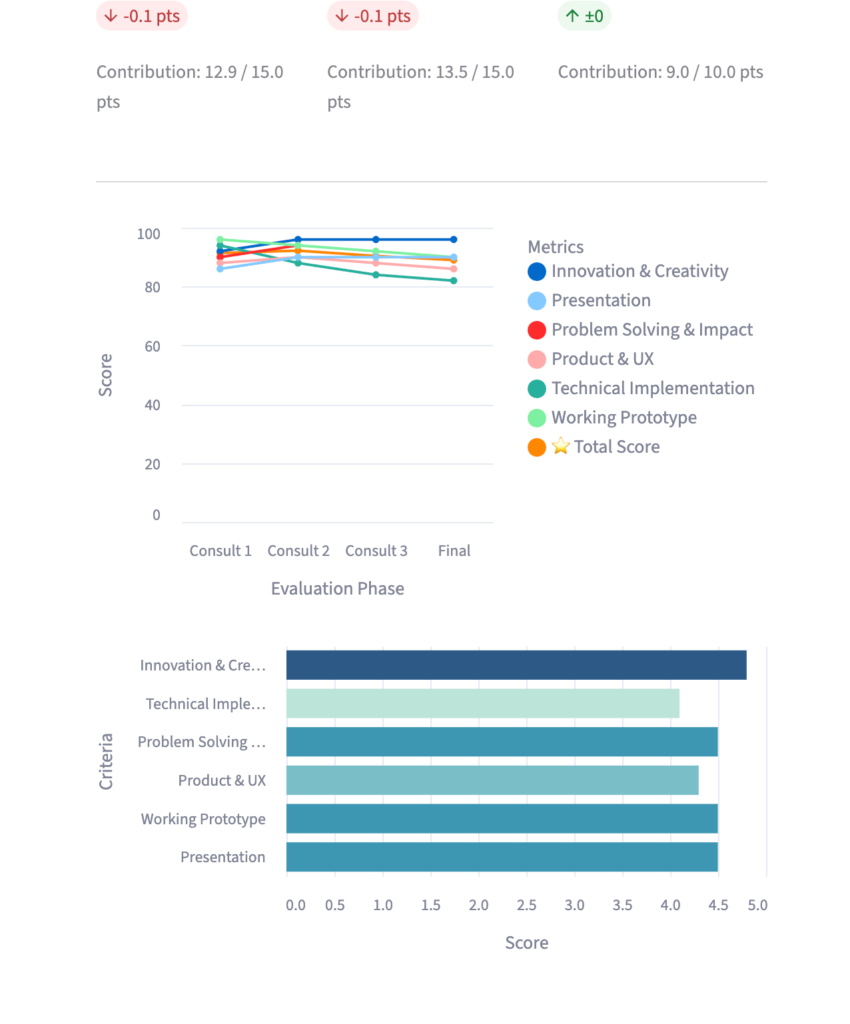
Before the final submission, each team can get up to three rounds of “AI coaching.” The key is that the previous feedback is passed in as context for the next evaluation. “Was the security issue we flagged last time fixed?” “How’s the UX of the newly added feature?” — the AI builds on previous feedback and makes the team’s growth visible.
Seeing the score trend as a line chart works well as gamification, I think. When the trajectory of improvement — Consultation 1 → 2 → 3 → Final — shows up in the score, team motivation clearly goes up.
“Objection!” — Designing for Buy-In
If a team isn’t convinced by the AI’s evaluation, they can push back once. The AI judging panel re-deliberates with the full prior context and responds.
This is half entertainment, but I designed the other half in complete seriousness. When an AI’s evaluation is a one-way street, competitors walk away still stewing over “why did we get this score?” Giving them a chance to object creates a sense of buy-in about the evaluation. In judging, I believe that buy-in matters more than the score itself.
Bilingual — The Origin of This Project, and Its Most Essential Feature
The starting point of this whole project was “anxiety about English.” So bilingual support isn’t decoration — it’s the most essential feature.
In the output instructions to Gemini, I have it append a suffix to each field name for every output language the admin has configured, and fill in every feedback item in that language (for example, in an English–Japanese setup, paired _en / _ja fields; change the language combination and the suffixes change with it). Which languages to request is something the admin decides per event. On the viewing side, you just switch the display among the configured languages to instantly see the feedback in each one.
With this, competitors receive feedback in English while also being able to check it in Japanese — and I, as the judge, can join the discussion in English while referring to the Japanese feedback as my “draft.”
This is the very origin of the project, and the feature I wanted most.
Admin AI Chat — Answering the Judge’s “I Want to Dig Deeper”
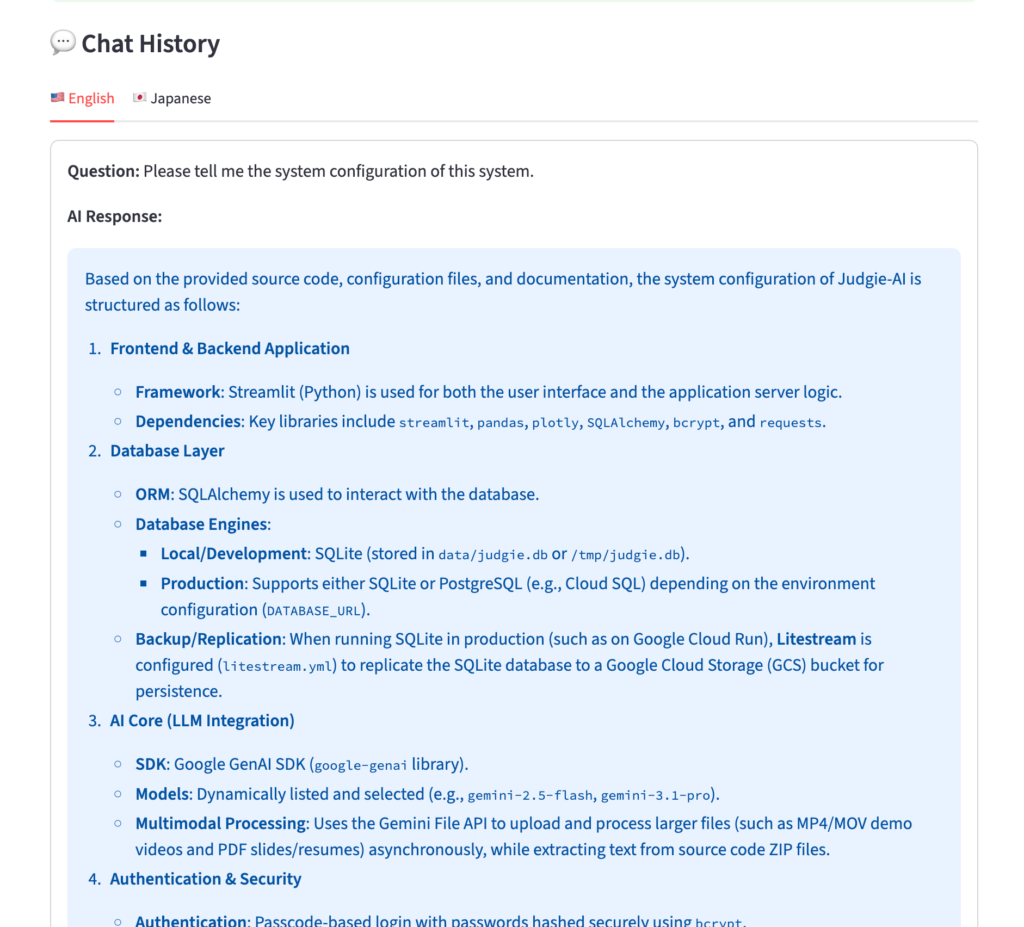
Imagining myself using it as a judge, there was a feature I immediately wanted: a chat where I can ask the AI directly about the submitted source code.
The parts you can’t see in a pitch or demo — “What library are they using on the backend?” “Are there any security concerns?” “What’s the design intent behind this architecture?” — I can throw those questions at an AI panel that holds the team’s deliverables as context.
Because the team’s submitted files — including source code, videos, and PDFs — are already available as context, the AI can answer questions based on the actual deliverables. To prevent hallucination, I also wrote an explicit constraint into the prompt: “for anything not contained in the context, answer that you don’t know.”
Export — So Teams Can Take the “Record of Judging” Home
I also built in a feature to export the judging content and the data stored in the DB as Markdown, all at once.
This environment won’t exist forever. Keeping it running indefinitely takes infrastructure and operating cost. Even so, there will surely be competitors who, after the hackathon, want to “revisit the judging feedback” or “use it for a team retrospective.”
So I made it possible to output each team’s judging feedback as a Markdown report, so it can always be kept on hand.
Going further, I imagine an approach where you drop Judgie-AI’s data as Markdown and feed it into NotebookLM — leveraging Google’s infrastructure so the team can keep using it as lasting knowledge.
Going Live — Running It at the Real Hackathon
And so came the hackathon proper, after the postponement. With Judgie-AI already built, I deployed it for real, fully prepared.
As teams uploaded their work, the AI judging panel analyzed the source code and videos and generated feedback in Japanese and English at blistering speed.
Before the final presentations, I had already gone through nearly everything teams submitted via Judgie-AI. When questions came up, I could check them through Judgie-AI as well.
As a result, I could spend most of my time not on “understanding the ideas in English,” but on “thinking about the value of those ideas.”
That mattered more than I expected. It let me return the work of judging — from understanding and writing English — back to what it should be: making the call. I built this initially as a tool to make up for my English. But because the AI returns reviews from multiple perspectives, I also caught points I would have missed on my own. I think the quality of the judging itself went up, too.

The Real Reaction — How Did Competitors Take It?
After the hackathon, I ran a survey with the participants and organizers. To this “unknown experience” of AI judges, the reaction was more positive than I’d imagined.
Quantitative Data (out of 5)
| Category | Question | Average |
|---|---|---|
| Competitors | Do you think the Judgie-AI panel’s evaluation was reasonable? | 4.27 |
| Competitors | Was the feedback from the Judgie-AI panel helpful in improving your product? | 4.46 |
| Competitors | Did Judgie-AI make the overall hackathon experience more engaging? | 4.51 |
| Organizers | Was Judgie-AI helpful in reducing the time and burden of judging? | 4.67 |
| Organizers | Was Judgie-AI helpful in assisting judging? | 4.67 |
| Common | Would you recommend using Judgie-AI at other hackathons? | 4.62 |
In Competitors’ Own Words
The following comments are reproduced as submitted.
- I really liked a idea, and personas and different ways to check the results great idea.
- I liked the way judgie-AI shared the thoughts from different personas, One small issue I faced is session is not being persistent, once hard reload and few minutes inactive it is asking for login.
- We uploaded our project in the first attempt. The Judgie-AI persona provided valuable suggestions that had not thought to us initially. We incorporated those improvements, which significantly enhanced the project and helped us achieve a 100% score. So we can delivery our project in good shape.
- It’s really good, never thought of AI being a Judge, and I liked the suggestions it gave and helped us on improvements.
- Very useful to understand the quslity at different prespective.
- very good support for Judge
- It helped the participant to get honest review and area of improvement
- The feedback comments on the project were helpful
- I liked the skill description of each judges. It was versatile and covered all aspects of scrutiny.
- Judgie-AI really provides some valuable suggestions to enhance the hackathon ideas
- Judgie_AI on its own was good to use, but there some some points to be noted. (1) The leaderboard did not seem like a good idea, since the way AI can look into a code and how the judges see the project may vary. having the leaderboard can affect that. (2) When we uplaoded our project in the AI tool, it gave us analysis on a completely different project that was not even closely related to ours.
- Currently, ratings are provided for each parameter when participants upload their source code. However, when a specific parameter receives a lower rating, it would be helpful to clearly indicate what needs improvement so that participants can focus on those areas and enhance their product.
- I really liked we have a different agent for judging different criterias and the comments provided by those agents. May be also if it could measure the topic we have chosen for hackathon and weighed with the other topics and organized leaderboard that would be more appealing.
- Excellent initiative
- I think the technical implementation evaluation was a little buggy. In our code, we had multiple frontend applications, multiple backend folders (for our fastapi central server, our slack, and our DB), as well as a dedicated Slack folder. However the evaluation seemed to skip most of the tech implemented and focused only on the Slack folder itself.
- The interaction, scoring mechanism was easy. Also it created a preparatory work and reduced burden on Judge in last minute. I really liked the idea
The gamified element of watching the score chart rise through the mid-event consultations, together with the feedback from realistic AI personas, contributed a lot to raising the energy of the whole hackathon.
But what made me happiest wasn’t the high scores. What mattered most was that Judgie-AI’s feedback was pushing multiple teams’ product ideas forward. I had built it to make judging easier — yet in practice, multiple teams incorporated AI feedback and improved their products themselves. A tool I’d made to help the judge had, without me noticing, become a coach that accelerated team growth.
What I would do differently
Session management and framework choice
Because I’d planned for a solo half-day hackathon, I optimized the pre-production tech stack entirely for speed and ease of setup. Streamlit, which I chose for that reason, isn’t particularly strong at building robust session persistence and auth flows — it’s better suited to small, short-lived tools. I went all-in on speed at first, but once the hackathon was postponed, that assumption no longer held, and I should have switched to an architecture better suited for solid session management. Patchy workarounds led to bugs. I want to improve this so it becomes a much less stressful experience to use.
Performance under deadline traffic (access spike right before submission)
This time I ran it with Cloud Run + SQLite + Litestream: a minimal setup where everything completes inside a single container, keeping infra cost low. On the other hand, Litestream’s constraints mean it can’t properly handle autoscaling. There were Streamlit session issues as well, and honestly I didn’t expect heavy usage — so I went with this non-autoscaling setup. It ran fine for most of the hackathon, but it couldn’t keep up in the last few hours before the deadline. A spike right before the deadline is easy enough to imagine — I was too optimistic. Next time I’d separate the DB into something like RDS and design for autoscaling under peak load.
On the validity of feedback
Some teams found the feedback extremely useful; others didn’t. Those who found it useful were in the majority, but a few teams didn’t. I came to see this as a broader evaluation-design issue, involving both hackathon operations and Judgie-AI’s judging criteria.
In this hackathon, there were roughly two types of teams:
- Process-improvement: “improving internal operations and automating existing processes”
- Business: “proposing new customer value, including monetization and market potential”
Because the AI judge panel was given criteria emphasizing business impact and innovation, it naturally produced that kind of feedback. For teams focused on day-to-day operational improvements, those axes can feel mismatched.
That said, Judgie-AI shares the evaluation axes with competitors up front. In that sense, it’s arguably clearer and fairer than humans, who might unconsciously shift criteria while giving advice. Next time, aligning expectations upfront or splitting evaluation axes by participation category (process-improvement vs. new business) could further increase the sense of buy-in.
Looking Back — Releasing It to the World as OSS
Judgie-AI was born from a personal problem I had: “anxiety about judging in English.” But in the arena of hackathons and evaluation, it has the potential to become software that helps with a universal problem people around the world face. As a first step — to make running hackathons easier and to deliver richer, fairer feedback to competitors — I’m placing the source code at yosuke1024/Judgie-AI on GitHub and releasing it as OSS (open source).
This is an improved version that resolves the session-management issues that arose from going all-in on speed. The survey results above are from the version we ran at the hackathon. The OSS release addresses the session and framework issues we hit in production. I’ve also revisited the UI and framework. You can deploy it on Railway, and the README includes a deployment link. It should be usable within a few minutes.
Evolving Further
During development, I had a genuinely exciting realization: this format isn’t confined to hackathons. Swap out the criteria and personas, and it becomes a more general-purpose AI evaluation platform.
As I prepared the OSS release, I extended the template-sharing idea from the hackathon into something anyone could publish and load — no code changes required. Judgie-AI evolved further:
- JSON Templates — Define personas and evaluation criteria for non-hackathon use cases in JSON and pick them as templates.
- Gist Integration — Publish a template to a GitHub Gist and load it freely from that URL.
Right now, beyond hackathons, I’ve published the following templates as Gists:
Riding the momentum, I seriously considered building an entire marketplace for publishing templates … but no — I came to my senses, realizing it was getting way ahead of myself for software nobody’s even using yet, and pulled back.
Even after release, Judgie-AI evolves as templates grow and get swapped out. The more personas and evaluation criteria for non-hackathon use cases get shared, the more the platform should grow in both breadth and depth.
That said, Judgie-AI still has open challenges. How the quality of the AI’s evaluations would turn out was something I couldn’t know until I actually ran it. Would it produce coherent evaluations? Would it just hand everyone scores that were too high? Honestly, that worried me. Having a track record from the hackathon, with high marks from competitors, at least gave me the confidence that the hackathon template is good enough to publish as an official template.
Even so, how to guarantee quality as I add more templates going forward — that answer isn’t in my hands yet. Judgie-AI is mid-experiment, and the track record is still thin. Look at the actual prompts and I’m sure many of you will think, “you could do this so much better.”
Making it more useful together with many people is my wish. An Issue, a Pull Request, or even just introducing a template you’ve put on a Gist — anything works. If I can grow this uncertain experiment into a platform people can trust, together with all of you, nothing would make me happier.
📢 [Coming Next] How I Released an App With an Org of AI Experts — Without Writing a Single Line of Code
Judgie-AI’s “multi-persona judging debate” design — those five judges were actually a by-product of the 14-member AI expert organization I built for “PixMeal,” the AI meal-logging app I developed privately.
In the next post, I’ll share a development journal where I imposed one rule on myself — “don’t write a single line of code” — stood up a virtual organization of 14 specialists inside the AI (CEO AI, UX designer, white-hat hacker, legal, and more), and sprinted all the way to a Google Play / App Store release. This one also ran far beyond a simple dev journal and is shaping up to be a massive post.
It should be out within a few weeks, so if you found Judgie-AI interesting, I’d love it if you followed me on X and starred it on GitHub while you wait!
We’re Hiring
At Money Forward India, we’re looking for engineers with the drive to take the problems and absurdities right in front of them and hack through them with AI and a modern tech stack, on their own initiative. I hated judging in English, so I solved that absurdity with a tool. Money Forward India wants engineers who, rather than “accepting the problem,” reshape the problem itself. If any of this resonated with you, I’m sure we can do something fun together. Let’s talk.