
Who This Post Is For
- (Junior) Engineers inheriting or taking over a system with little or no handover
- Teams replacing polling-based integrations with event-driven Kafka architectures
- Platform builders who need to define clear ownership boundaries between infrastructure and product teams
A Bit About Me
I’m Takudai Kawasaki, a backend engineer working in the Account Aggregation Division at Money Forward, primarily using Go and Apache Kafka. You can reach me via LinkedIn or X.
The Problem
There is a big difference between using Kafka and owning a product built on a Kafka foundation. I learned this the hard way when I took over the event-driven product, roughly six months into my career as a new grad at Money Forward.
The event pipeline is a Publisher/Subscriber application built on our Kafka infrastructure (Amazon Managed Streaming for Apache Kafka, or Amazon MSK) for the Aggregation domain.
It was my first time owning a product end-to-end: from inheriting a partially built system with no handover, to defining its boundaries, onboarding new product teams, and taking full responsibility for its reliability.
This post is both a technical overview of the pipeline’s architecture and a reflection on what it means to own a product you didn’t build. It’s the kind of document I wish I’d had when I started.
By the time I joined the project, the engineers who had originally built it had already moved on. With no formal handover and limited documentation, understanding the original design intent was extremely difficult. Comprehending the existing system felt like assembling a puzzle with missing pieces: scattered code, implicit decisions, and countless unknowns. Before I could move anything forward, I had to piece together what existed and why — and that turned out to be the critical first step.
The Context: From Polling to Push-Based Events
Money Forward’s backend has historically been a large monolithic application. The company has been gradually decomposing it into loosely coupled, domain-oriented services (for more background, see the Tech Day 2024 talk on this initiative). During this transition, two key actors are relevant to this story:
- Aggregation Service — the upstream system that manages users’ linked financial accounts and their asset data (balances, transactions, etc.).
- Downstream product teams — multiple product teams (e.g., household budgeting, accounting, expense management) that each need to know when a user’s asset data changes so they can update their own features.
Before (the polling problem): Each product team independently polled the Aggregation Service’s database to detect asset data changes. With N products, this meant N separate polling implementations — each team writing its own change-detection logic, each hitting the same database on its own schedule. This duplicated engineering effort across every team and added unnecessary read load to the upstream database.
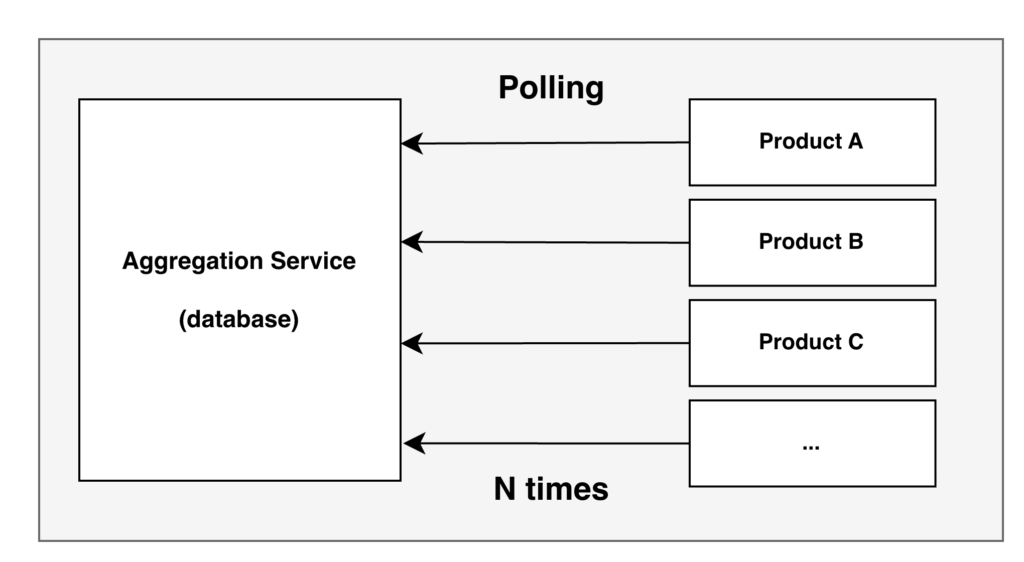
After (the event pipeline): The event pipeline replaces these N polling implementations with a single push-based model. It detects asset data changes once in the Aggregation Service and broadcasts notifications to all subscribers via Kafka. Each product team simply subscribes to its own topic — no polling, no duplicated detection logic.
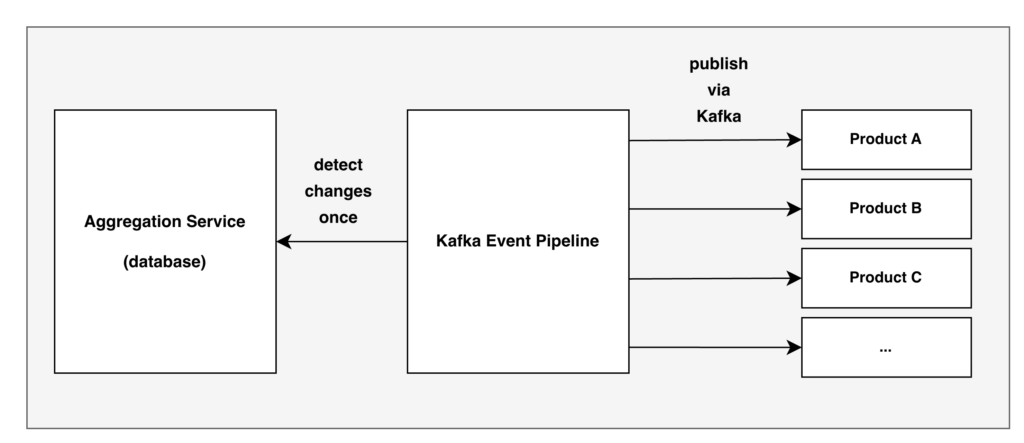
How the Event Pipeline Works
At a high level, the event pipeline is responsible for publishing aggregation event notifications using Kafka. It consists of four main components:
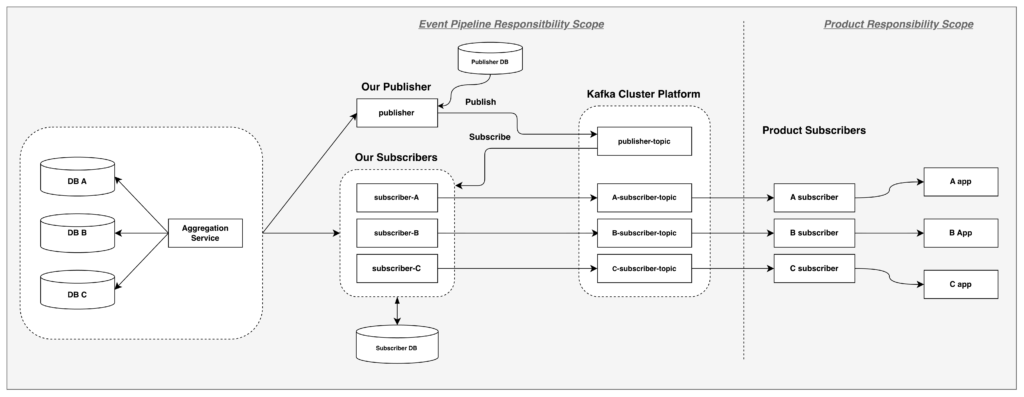
Note: Topic names like publisher-topic and {product}-subscriber-topic are examples used throughout this post, not the actual topic names.
- Publisher: A shared application that retrieves aggregation change events and publishes them to the central Kafka topic (
publisher-topic). It processes a list of users whose assets have been updated. - Subscriber: A product-specific application managed by our team that subscribes to events from the central topic, enriches them, and publishes to product-specific output topics (e.g.,
{product}-subscriber-topic). Each subscriber serves a specific product — there are currently multiple active subscribers.Product teams then build their own consumers to read from these output topics. - Aggregation Service: The upstream service that manages account assets.
- Kafka Cluster Platform: The managed Apache Kafka infrastructure (Amazon MSK) provided by AWS.
Publisher and Subscriber Flow
Publisher Responsibilities
- Implements application-level Change Data Capture (CDC). Unlike log-based CDC (e.g., Debezium), the publisher detects changes by querying the Aggregation Service for users whose assets have changed, using a sequence-based cursor to track its position.
- Publishes lightweight events (
user_id, sequence number, timestamp) to thepublisher-topicKafka topic — just enough to signal that a change occurred, not what changed. - Writes to Kafka using Kafka’s transactional API and persists state to the database to ensure data integrity (no lost or duplicate change signals).
Subscriber Responsibilities (owned by the pipeline team)
- Consumes the lightweight publisher messages from the central topic.
- Filters users by product relevance (each subscriber only processes users relevant to its product).
- Determines the change window (using timestamps and sequence numbers). It then fetches the actual changed asset data from the Aggregation Service.
- Publishes enriched messages to a product-specific output topic (
{product}-subscriber-topic). These messages contain time windows, sequence ranges, and lists of changed assets — giving downstream products everything they need in a single event.
Product teams consume from these output topics with their own consumers and downstream business logic.
A deliberate two-stage message design separates concerns:
| Stage | Topic | Content | Purpose |
|---|---|---|---|
| Publisher | publisher-topic | User identifier, sequence number, timestamp | Signal that a change occurred |
| Subscriber | {product}-subscriber-topic | Time windows, sequence ranges, full asset data | Deliver actionable change data |
A key design decision was grouping changes by user. In Money Forward, a single user can link multiple bank accounts, credit cards, and other financial services. When assets change, downstream products often need all related changes for that user at once. For example, a household budgeting product needs every updated account balance to recalculate a user’s total assets, and an expense management product needs all new transactions across accounts to categorize spending correctly.
If changes were delivered per-account instead, each product would have to collect and correlate scattered events back to the same user, handling timing gaps when multiple accounts update at different times. The subscriber avoids this by grouping all of a user’s changes into a single message, giving downstream products a complete, consistent view of what changed.
Ordering and Correctness
For financial data, order is critical. We set each message key to a hashed user_id, giving every user consistent partition routing so their events are always processed in sequence. We optimized for correctness over raw throughput.
// Idempotent processing pattern
func (s *Subscriber) Handle(ctx context.Context, msg Message) error {
lastProcessed := s.repo.GetLastProcessed(msg.UserID)
if msg.Sequence <= lastProcessed.Sequence {
return nil // Already processed, skip
}
// Process and update state atomically
return s.processAndCommit(ctx, msg)
}By tracking the last processed sequence per product, the subscriber can safely skip duplicate messages.
Reliability and Observability
To guarantee message delivery and durability, we tuned the following producer and consumer settings:
# Producer Settings
required_acks: -1 # All in-sync replicas (ISR) must acknowledge (equivalent to `acks=all`)
max_attempts: 10 # Retry up to 10 times
backoff_max: 1s # Cap retry delay
# Consumer Settings
read_timeout: 60s # Allow for slow consumersAdditional operational configuration:
- Retention:
retention.ms = 1209600000(two weeks), giving us a substantial buffer for recovery or debugging. - Structured labels: Every pipeline component is tagged with labels that feed into our monitoring platform, enabling per-service dashboards, alerting, and Service Level Objective (SLO) tracking without manual configuration.
- Infrastructure-driven configuration: Key runtime parameters like partition count are injected via deployment manifests rather than hardcoded, allowing infrastructure changes without code redeployment.
- Kafka CLI for debugging: We maintain a dedicated Kafka CLI pod in the cluster, pre-configured with Amazon MSK credentials and SSL certificates, giving the team immediate access to tools like
kafka-console-consumerandkafka-topicswithout local tooling or VPN tunnels.
What we monitor:
- Consumer lag per subscriber
- Message throughput rates
- Error rates on Aggregation Service API calls
- Database connection health
- Pod restart counts
Defining the Product’s Boundaries
When inheriting a system, the hardest part was not writing code — it was figuring out where the event-driven product ends and where product teams begin. None of these boundaries were written down, so I had to reconstruct them from code paths, team conversations, and trial and error. This mirrors the company-wide approach to service decomposition: draw clear domain boundaries. The same principle applies at the product integration level in this case.
What the Pipeline Provides vs. What Product Teams Provide
The event pipeline provides:
- Publisher service (change detection → central topic)
- Product-specific subscribers (e.g., subscriber-{product}) that enrich and republish to output topics
- Infrastructure (Kafka Cluster Platform, database, monitoring)
Product teams provide:
- Their own consumers that subscribe to product-specific output topics (
{product}-subscriber-topic) - Downstream business logic and data processing
Monitoring boundary: The pipeline monitors everything up to and including the output topic. Once a message is published to a product-specific topic, monitoring responsibility shifts to the product team.
The Output Contract
The real contract with product teams is the output topic message schema:
{
"user_id": "string",
"time_window": { "from": "ISO8601", "to": "ISO8601" },
"sequence_range": { "from": "integer", "to": "integer" },
"accounts": ["string"]
}Product teams do not need to understand Kafka internals or the subscriber code. They only need to consume from their designated output topic ({product}-subscriber-topic) and deserialize this schema. The output topic message is the contract.
Onboarding Flow
Integrating a new product with the event pipeline follows a structured process:
- Intake form: The product team fills out a requirements questionnaire describing what asset data they need.
- Kafka access: The team gains access to the Kafka infrastructure.
- Development: Our team develops the corresponding subscriber, while the product team develops their consumer for the output topic (using a local tool that simulates the subscriber).
- Staging: Our team creates the staging topic and the product team validates end-to-end.
- Production: After staging validation, the production topic is created and the subscriber goes live.
Schema Evolution and Compatibility
Current State: JSON Contracts
The JSON-based schema was an inherited design decision — already in use by the time I took over the pipeline. The pipeline currently uses the JSON contract shown above as its output topic schema. Any changes to this schema require careful coordination with product teams, since raw JSON offers no built-in mechanism for backward or forward compatibility. In practice, our team manually communicates schema changes and product teams must add defensive parsing to handle missing or unexpected fields.
While the current JSON approach works, it introduces coordination overhead that motivated our planned migration.
Future Direction: Protobuf + Schema Registry
Money Forward has standardized on Protobuf + Schema Registry for event-driven messaging, and the event pipeline will be aligned with that standard in the future.
Together, Protobuf and Schema Registry address the limitations of raw JSON:
- Wire-level compatibility (Protobuf): Unknown fields are silently ignored by older consumers, and new fields receive sensible defaults — our team can evolve the schema without breaking existing product consumers.
- Deployment-time enforcement (Schema Registry): Compatibility rules are checked before a schema change reaches production, preventing breaking changes from ever being published.
- Developer experience: Product teams get code generation with compile-time guarantees on field names and types, eliminating manual JSON deserialization and defensive parsing.
Uncovering Compliance Gaps
Defining the product’s boundaries also surfaced undocumented compliance obligations. Through conversations with the Aggregation team, it turned out that compliance checks and data privacy requirements had not yet been fully addressed. After escalating to the appropriate stakeholders, development was paused so teams could evaluate alternatives.
The code worked as designed — but the design had never been validated against compliance requirements, and there was no way to confirm it was compliant. Uncovering this put the project on hold, but it was far better than shipping a system that could potentially violate compliance.
What I Learned
- Inheriting a product with no handover: Taking over a system mid-development when the previous owners have left is daunting, but it is survivable.
- Do software archaeology: Read every artifact — code, configs, deployment manifests, CI pipelines, Slack threads, decision records. Trace data flows end-to-end, build a dependency map, and write down your findings as you go — this becomes the documentation that didn’t exist.
- Question everything: Don’t assume prior decisions were settled just because work moved forward — whether that’s architectural choices or cross-cutting concerns like compliance and data privacy. Identify the right stakeholders and verify for yourself.
- Draw boundaries first: Just as the company-wide decomposition initiative draws boundaries between domain services, we clearly separated infrastructure responsibility (the Kafka Cluster Platform) from application responsibility (the publisher/subscriber layer). Getting explicit agreement on ownership was essential.
- List what your team owns and what integrating teams own — infrastructure, subscribers, output topics, consumers, monitoring — and write it down so both sides can point to it.
- Infrastructure is part of the product: Even if a separate team manages infrastructure like the Kafka Cluster Platform, we still need to understand configurations like acks, retention policies, and replication factors in the world of Kafka — they directly affect our application’s correctness and reliability.
- Make it easy for others to get started: Provide ready-to-use examples, clear documentation, and a step-by-step onboarding process so product teams can integrate without guesswork.
Further Reading
The software archaeology approach described above — tracing code, configs, and data flows — reveals what the system does. But to understand why it was built that way, I needed external knowledge. For example, the code set acks=-1 and used hashed user IDs as message keys, but only the Kafka documentation explained why these choices matter for durability and ordering. Similarly, the kafka-go library source clarified runtime behaviors — like transactional writes and consumer group rebalancing — that the codebase relied on but never documented.
- Apache Kafka Documentation — core concepts underpinning the pipeline’s design
- Amazon MSK Best Practices — operational guidance on the managed Kafka infrastructure the pipeline runs on
- segmentio/kafka-go — the Go client library used in the pipeline’s implementation