
Introduction
Hello, I’m Jackie. I’m working as a backend engineerat at Money Forward within Group Management Solutions division, we are crafting products specialized in Consolidated Accounting . This article explores Batch Job Management solutions, providing insights for backend developers, architects, and professionals interested in distributed systems architecture.
Background
Our application regularly processes files uploaded by users. Currently, this processing occurs within the API pod itself. Although we handle this asynchronously and notify users via websocket upon completion, we face several challenges:
- Job Loss: Tasks are lost when pods crash or during deployment
- Scalability Issues: The system struggles to scale effectively when processing large volumes of data
Solution Evaluation
We conducted an internal architectural review where team members presented various proposals. The following options were considered:
- Database Approach: Using MySQL for job metadata management with locking mechanisms to prevent duplicate processing
- Message Queue Integration: Implementing industry-standard queuing systems (Kafka, SQS)
- Serverless Architecture: Leveraging AWS Lambda for job handling
- Redis Stream Solution: Utilizing Redis as a message broker
After thorough evaluation, all proposals demonstrated technical viability. Recognizing that architectural decisions involve careful trade-offs, we selected Redis Stream based on the following considerations:
- Vendor Independence: Avoids tight coupling with specific cloud providers (AWS Lambda, SQS)
- Infrastructure Efficiency: Requires no additional infrastructure costs or setup overhead
- Development Optimization: Leverages our existing Redis implementation, reducing implementation effort
Redis Stream Introduction
Redis Streams, introduced in Redis 5.0, provides an append-only log data structure similar to Apache Kafka. This feature is engineered for high-throughput messaging and efficient stream processing operations.
Key Capabilities:
- Append-Only Structure: Data entries are sequentially added to the stream with unique identifiers
- Consumer Management: Supports both individual consumers and consumer groups (similar to Kafka’s consumption model), ensuring each message is processed by exactly one consumer within a group
- Data Persistence: Stream data resides in Redis memory with configurable persistence options
- Reliable Delivery: Implements acknowledgment mechanisms within consumer groups, guaranteeing processing confirmation
Implementation Workflow
Message Distribution
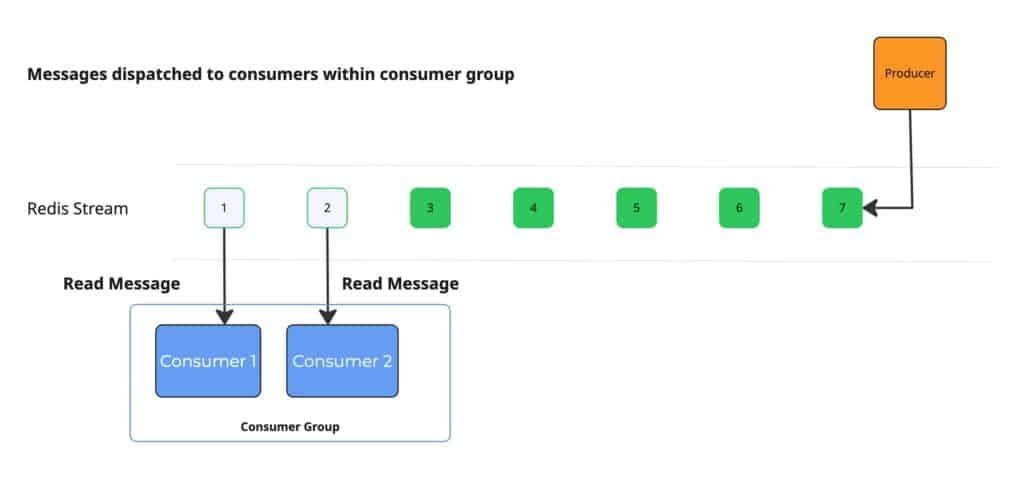
- Consumers subscribe to the Redis stream using three parameters: stream key, consumer group name, and unique consumer identifier
- Each consumer requires a unique identifier; in our Kubernetes environment, we utilize the pod hostname which is guaranteed to be unique
- Producers append messages to the Redis Stream
- Messages are distributed to consumers within their respective consumer groups
- Upon dispatch, messages are placed in a Pending Entries List (PEL), indicated visually by a gray background
- Message processing order (sequential or parallel) within a consumer depends on the consumer implementation
Message Acknowledgement

- After successful processing, consumers send acknowledgment information for the completed message
- Upon acknowledgment, messages are removed from the Pending Entries List
- If a consumer terminates during processing, the message remains in the PEL for recovery
Message Recovery Process
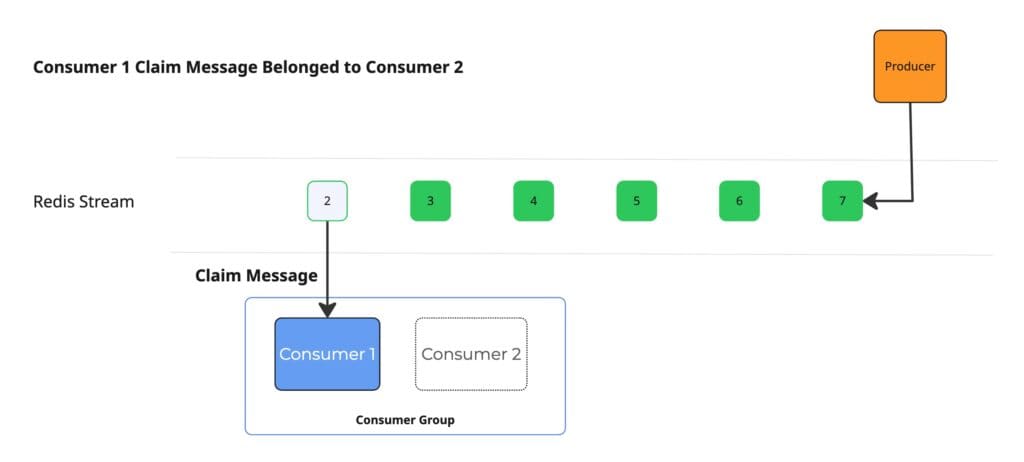
- Alternative consumers must claim pending messages from terminated consumers, otherwise messages remain indefinitely in the PEL
- Our implementation includes a scheduled background task that periodically inspects and reprocesses the pending list using Redis’ specialized commands
- To prevent duplicate processing, Redis accepts an idle time parameter, claiming only messages that have remained in pending status for the specified duration
- We implemented an advanced heartbeat mechanism to address edge cases: consumers regularly send heartbeats to Redis, and before claiming a message, we verify the original consumer’s heartbeat timestamp—if the consumer is still active, the claim operation is skipped
Consumer Recovery Mechanism
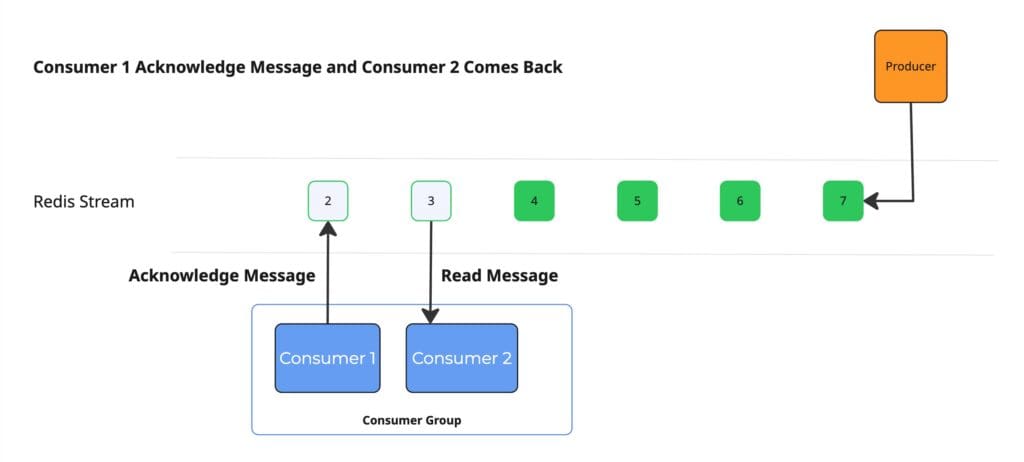
- When a consumer restarts, it rejoins its consumer group and immediately becomes eligible to receive new message assignments
Conclusion
The implementation of Redis Streams as our job processing system has substantially improved the resilience and scalability of our file processing workflow. By leveraging Redis’ native capabilities, we’ve successfully addressed our primary challenges:
- Resilience: Jobs are no longer lost during pod crashes or deployments, as the message state is preserved in Redis Streams
- Scalability: The system now efficiently handles increased processing loads by distributing work across multiple consumers
- Reliability: Our heartbeat mechanism ensures accurate message tracking and prevents duplicate processing
- Recovery: Failed jobs are automatically reprocessed through our claim system, ensuring no task is left unfinished
This architecture provides a vendor-neutral solution that integrates seamlessly with our existing infrastructure while maintaining operational simplicity.